
A high volume, highly available cron pattern
There are many options for periodic work, and they're often stack specific. If you're using Sidekiq, there's a plugin. If you're running on Heroku, there's an add-on. If you're running on Kubernetes, there's a feature. There are many tutorials about hooking into localhost cron daemons.
These might be good options for your system. But as the number of tasks increases, and if you need robust availability, the external cron pattern is worth investigating. I also like it for its development, monitoring, testing, and configuration simplicity.
The pattern is to have an external system call your APIs constantly. Each call runs scheduling logic to check on the current situation. If it's time to act, take action; if not, it's a cheap check.
Instead of a cron rule on each application server...
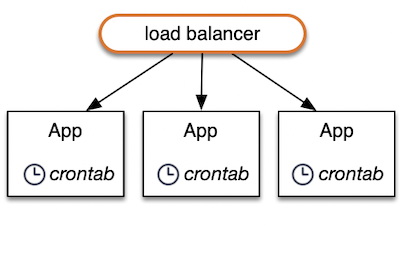
... it's just another API call:
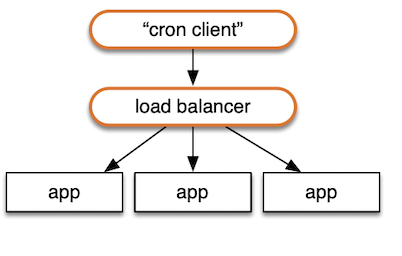
Consider a service with 1000 accounts, and each one needs to be looked at by your scheduling code once a minute. This "cron client" would call the service once per account per minute. Each call is handled by whatever node is available, as determined by the load balancer and health checks.
Scaling
I usually use a range or prefix as a parameter in each call instead of a full ID, batching work vs. calling the service for every distinct piece of work. In many systems, entity IDs have a UUID component and it's straightforward to split them into groups (there should always be a way to split up the work, even with non-contiguous integer IDs).
For example, say we are still looking at accounts, their IDs have a UUID component, and we want 16 groups. The cron client makes 16 calls per minute, each with a different hex character prefix. The combination of all 16 covers all possible IDs. A sample call would be "check scheduling on accounts with prefix 'b'." The service code will query all accounts with that prefix and handle the scheduling of each one in a loop, threads, etc.
That is scalable because you can split the ID space into as many distinct groups as needed for your system. If you had 100k customers, you could make 1k calls that handle roughly 100 accounts each and scale the nodes behind the load balancer to whatever is needed for that workload. As the number of accounts increases from zero to 100k, you occasionally need to adjust the spread with a simple configuration change.
Handling one distinct 'check' job per call could still the best choice at scale; what makes sense is going to be application specific.
Availability
A large fleet could be a nightmare to configure if you wanted to piggyback off local cron daemons and still spread out the load well. On top of the extra configuration complexity, consider how rolling deployments to the app nodes would play out. And how often will a machine become unresponsive or have performance issues? You could easily suffer a scheduling gap for certain groups in the ID space as the problem is addressed.
Configuring a particular node to trigger the recurring work, as some people recommend, would likely be worse. You may need to turn to a leader election system if you want high availability. That's a lot of extra complexity and monitoring.
But with calls hitting a load balancer and being distributed to available nodes, the work continues no matter what happens because nothing is pre-assigned to a specific node. We have a stateless system. The cluster can scale up, nodes can gracefully stop work with typical load balancer draining patterns, and new code can be deployed progressively and seamlessly. In my setup, at least, all of that comes for free, and they are all well-worn patterns in our industry.
The cron client itself is a potential availability issue.
As a baseline, I've found Amazon EventBridge to be very reliable on its own. You can create rules to fire AWS Lambda functions every minute, which then call your API. There is a team staffing the oncall for EventBridge around the clock. And I could fit the entire system into the AWS free tier, which is great. It's a good value even above the free tier.
For redundancy, consider running a duplicate configuration in another region. In the unlikely event that EventBridge (or equivalent) fails in one region, it is even more unlikely that it would simultaneously fail in the second region. In the time it takes to respond to your alarms, the second region will still be pinging away at your service. This will reliably achieve an "at least once per minute" goal, and in most hours, it will be twice.
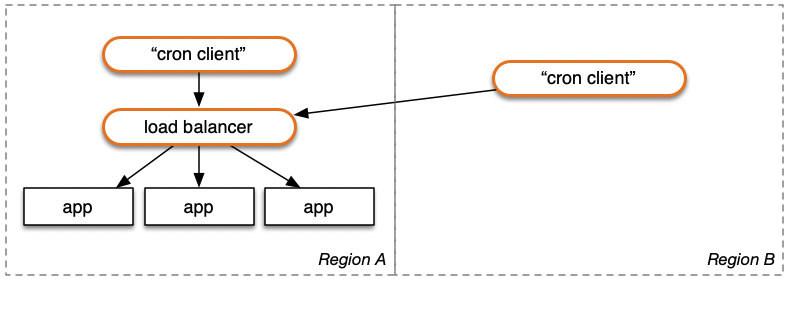
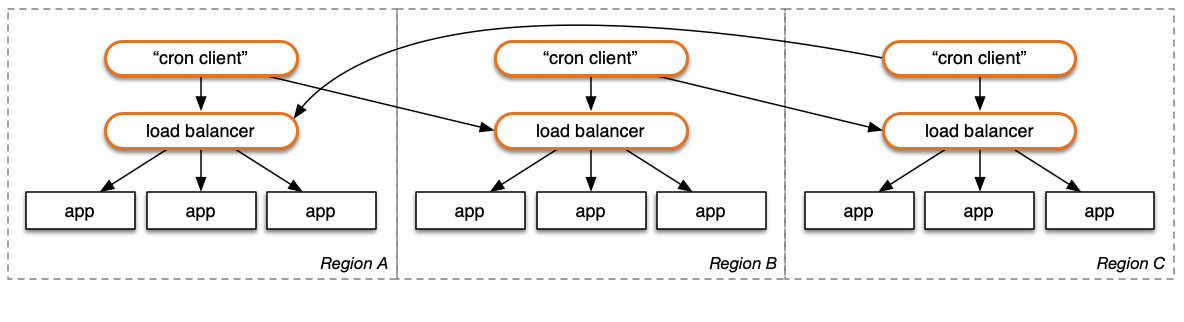
Is your application itself multi-region? Every region's EventBridge (or equivalent) can be configured to fire off functions that call every region. To ensure at least once a minute, with three regions cross-configured, you would end up with each region getting called three times a minute. There are subset configurations to explore (each region calls N-1 regions, etc.); a full NxN setup is likely overkill in most cases.
Checks, not triggers
For this pattern to work well, the application code needs to be able to handle many duplicate calls per minute (or whatever time period you choose). In order to achieve one highly reliable scheduling "check" per time period per group/ID, the code needs to be able to handle more than one of those calls per period.
Continuing with the account example, the API calls are a check on an account's scheduling status; they are not a definite trigger to take action on that account.
There are a number of ways to organize it as a check, but I've found it best to evaluate the current state of the system against the current time. This allows you to receive multiple calls close together, where one is effectively a no-op. But remember, the goal is to make sure at least one check happens per minute. The scheduling logic will govern whether an action is triggered or not, and that has everything to do with the context and history of actions, not the number of times the check function is triggered.
If you need to ensure something is checked or happens once per minute in the same second each minute, that is a different problem and the pattern would need to be different. On AWS, you may still rely on EventBridge rules for that. Your high availability approach would need to be more carefully planned: the tighter the time window (one second is still a window), the more challenging it is to kick off redunancies if the first mechanism fails.
Testing
The development and testing situation is good. You can dictate exactly when the scheduling check occurs in both unit and integration tests.
Above, I mentioned being able to accept a prefix. If you accept arbitrary-length prefixes, for testing, the "prefix" can be the entire ID, and the operation can only work on that one entity. In the case of an account: for tests, you can create an account with a new ID, trigger scheduling work for it, look at effects, etc.
You can also split out the current time as a parameter. Doing this in an RPC operation is possible; one approach is to create a parameter that's an optional override that will be used instead of the current time. You or your team might frown upon that (leaking a testing detail into an externally facing API, even if it is a private operation).
Regardless, I'll recommend structuring the core scheduling logic like that. Create a function that takes all relevant information as parameters, including the current time and any other needed information (time of the last action taken for X, result history of previous actions, etc.). The function should return any actions that need to be triggered. So, this is a pure function with no side effects, and every scenario you can think of can be covered (and it fits well with property testing à la Quickcheck).
This way, the vast majority of the testing is done on this core function directly. As long as you cover all of the relevant input permutations in those tests, only sanity check integration testing is needed for these repetitive calls to the API. They are just operations that gather those inputs periodically and call the core function; the integration tests need to focus on whether the wiring is correct, not every scheduling situation.
Perhaps the most important property of the system: you won't need tests to wait several minutes to exercise several scheduling iterations and their effects. That is the pits. Slow development and CI cycles will aggravate everyone. And they encourage the team to add fewer tests in the long run because no one wants to make the test suite duration even worse.
Development
It rarely happens, but there are a few times that I want to run everything locally and have the system operate like the real deployment with once-per-minute calls to these operations.
A standalone client in a while loop from the shell is all you need here (sleep for a minute, call the APIs, go back to sleep, etc.). I use the same code that runs in the Lambda functions but triggered from the command line instead.
Monitoring
A nice property of this setup is being able to monitor it just like it were a customer-facing API. All the monitoring you already have for call volume, errors, latency, etc., will apply.
As it grows, you can create a separate set of nodes behind a separate load balancer for this system. This lets you "right size" the deployment separately and makes it particularly easy to keep track of ongoing work vs. customer-facing APIs in the dashboards and alarms. But there are ways to categorize the metrics if you are sharing nodes or if it's all serverless functions.
Categorizing it separately is important because the call volume and call durations for this system will likely be orders of magnitude higher than your customer traffic. Customer traffic can get lost in the noise; the isolation is good for spotting patterns and setting appropriate alarm thresholds.
Tracing
This has little to do with the external operation approach, but with so much recurring work, you may want to approach distributed tracing differently.
I created an interceptor between trace collection and the process that posts the traces to a storage/analysis service. Different from the normal technique of sampling, only errors or operations that are too slow get past this interceptor. The number of calls in this system would be far too costly to handle in the same way as customer traffic (where I want a much higher sampling rate).
Security
There are valid concerns when you create externally facing operations that are never meant for customers to call.
There are a number of approaches, and they can be layered.
- A special authorization rule. The configuration should specify what accounts/API tokens could ever be used for system operations, and there should be friction to change it.
- Support a second token as a double-check / increased randomness.
- Obfuscated API paths. No matter the path, I recommend returning 404 if authorization fails on these so they are not discovered as easily. But you could make the path very hard to guess in the first place to avoid people using timing information to determine if a 404 is a "real 404" or an authorization failure.
- Network access. Even with the same codebase, the system APIs can be deployed separately to an isolated network that is simply not accessible.
Multiple windows
You may have different activities that need to be triggered across different periods. Here are three real-world examples from Yupdates:
- Every input needs to be examined at least once a minute (even if an action might not be taken each minute)
- Analytics need to be run on each account every 15 minutes
- Garbage collection needs to run on each feed every 60 minutes
In the first case, we have a very high number of inputs, and one API call should not kick off work for all of them. As discussed above, either calling once per entity or once per subset of them will spread out the load.
In the second case, consider a requirement that it runs all analytics on the hour, on the :15, on the :30, and on the :45. In this case, either your cron setup should be configured to trigger at exactly those minutes or the "cron client" can be called every minute but it checks the current time and does not call the API unless it is one of those special minutes.
In the third case, garbage collection, the work doesn't need to happen in a specific minute; it needs to happen roughly once per hour per feed. It's best to spread the work across the hour. What we can do on the client side is add a time component when selecting the ID prefix/group.
Using the example of IDs with UUID components, the "cron client" still runs every minute, but instead of covering the entire ID space each minute, we divide it into 60 buckets. This is based on the current minute, 0-59. In minute zero, only 1/60th of the UUIDs are included. In minute one, the next 1/60th is included, and so on. Within those subsets, you can split them into more groups and make multiple calls to your API, each with a prefix.
So, we have prefixes based on 1/60th of the ID space and we created more specific prefixes within them to make the API calls during that minute. Every minute, roughly 1/60th of the feeds are garbage collected, and that work is spread across a configurable number of calls to the load balancer, and therefore spread across the fleet.
We could have organized cases two and three in the same way as the first case. There would be a full onslaught of calls, but the vast majority of them were no-ops. But there are simple techniques to avoid that.
Having that full onslaught is better for reliability, but if you don't have strict needs, this client-side suppression is a good choice. For example, in the garbage collection case, it is OK if there is an issue and the work waits an hour until the next round.
It depends on your needs and preferences; the main idea here is that in some cases you can add a little bit of logic in the "cron client" code that will limit the calls to your actual API, reducing noise and load.
Conclusion
I hope this sparked some thoughts about your high-volume cron/scheduling system and how it could work differently. I've seen so many tutorials about hooking into the local cron daemons that I thought it would be helpful to explain an alternative for systems that are looking for higher availability and less operational/design complexity.