
Serverless Rust Testing
In the system I'm building there are a significant amount of SQS messages that need to be processed asynchronously and Lambda is a really good fit for that. It is perfect for spiky workloads. You can control max parallelism easily. And it now has a native integration where Lambda functions are invoked with pending SQS messages without any extra work on your part.
Lambda's great. I think it's time to declare it boring. In the "choose boring technology" sense. As in it's a robust and well-worn solution.
But a significant problem I had was that most of my code is Rust. The Lambda experience with the major languages (e.g. Python) is categorically better. There are fewer gotchas, many more examples, and it seems especially true when trying to use the higher level tooling out there which I will get into in a minute.
Re-writing the pieces in another language like Python was not tempting as these Lambda functions are handling all the same data structures, re-using business logic, and calling the same dependencies as the main code base. It could be done, of course. But having multiple pieces of code doing the same things can be a giant hassle/waste (for small teams especially). And Rust is just far more maintainable to me.
Those reasons to stick with Rust outweighed any deployment inconveniences or performance arguments.
Performance-wise, Rust is surely faster than my main other candidate Python. So, maybe I'd pay significantly less money in the long run? Especially now that Lambda is billing at 1ms increments? I love that this happened but it's not really a significant factor in this case. The actual processing time is dominated by calling SQS, gRPC services, and/or DynamoDB.
Cost decisions all depend on the use case and expected load, of course, but the difference I projected is a not significant problem to me in the real dollars it would translate to. Something like Python would be completely fine here. I projected it would only increase the 30-40ms average runtime by around 10%. Waiting around is pretty efficient in any language. The great news recently was Lambda moving from 100ms billing increments to 1ms: a boon here regardless of the programming language. Very cool.
On a related note, I'm about to create something with Cloudflare Workers (using Rust/wasm) and that's quite a different billing model. Unlike Lambda, if you're awaiting subrequests, it doesn't actively count against your CPU time for that invocation. Sweet. It comes with trade-offs, of course. I'll probably write about what I learn in the future. I bet I'm adopting it for the directly customer-facing layer as my experiments so far on that platform have been pretty positive.
For Lambda and Rust, I ended up trying a number of the higher level frameworks and tools. The biggest factors in the decision were the deployment and testing support. I don't mind some setup pain if there are safe deployment mechanisms and fast, local testing that very closely approximates the real environment.
Serverless and AWS SAM are the two big ones that work with Rust and provide some local testing capability. There are a lot of other Python-centric ones. If you take local/mock testing out of the requirements, there are also some good infrastructure-as-code options: I'm eventually going to investigate CDK, Terraform, and Pulumi (which I use elsewhere). I have limited time and can't research a comprehensive survey of all of the options, unfortunately. I wish I could.
Fast iteration while developing is really important to me but none of those frameworks were fast for testing. The CLIs themselves take multiple seconds to respond for even simple tasks. Once Rust is involved, you're now into cross-compiling (to musl) and on top of that delay the frameworks are building/using Docker containers behind the scenes to run the tests. For a week or so, I was just running the lambci Docker image directly in automated integration tests, but that was not cutting it either. Still all too slow, the cross-compilation especially.
I ended up eschewing the frameworks altogether for local testing which is what I mainly want to write about.
There's now a thin layer that intakes SQS messages and parses the JSON payload into a strongly typed Rust data structure. This is in the bootstrap binary that Lambda runs. It reads environment variables for configuration. Locally, there's a completely separate binary that reads configurations from a dynamically generated file and polls for messages from a Redis queue (using LPOP/BLPOP). In both cases, the parsed queue payload is pushed into the 'real' code base which is identical in both cases. A classic "shim":
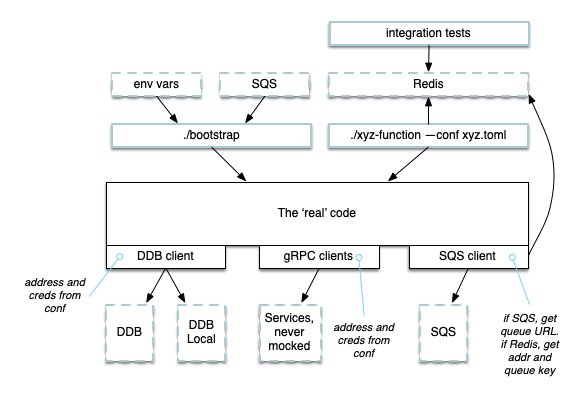
It's worked out well. I folded it into the same test framework that I wrote for traditional services. Redis is just another process that is launched from a group blueprint. The framework can launch groups of arbitrary binaries (either my own artifacts or system binaries like Redis) and Docker containers. Unique ports are reserved on the fly (via a SQLite database that is unique to each node) and written into the dynamically created configuration files. The processes can discover each other by role name so that you don't have to test one process at a time and mock dependencies - they can work together just as they would in the real system. The integration test itself can look up the same configurations and feed the test messages into Redis.
Importantly, many groups can be launched simultaneously, i.e., each integration test can launch its own group of processes. I can have hundreds of these running thousands of Unix processes even on my laptop. The Unix process model works quite well. Use it!
And that means cross-compiling to musl only happens for real deployments to Lambda. Anything I'm in the middle of coding is incrementally compiled and local (either OSX or Linux). The tests can be run nearly instantly. Both Redis and Rust binaries are extremely fast to execute and get to an operational state (mere milliseconds). The actual process wrangling is handled by the fast runit set of tools which the group management code triggers (here is a post on how to do that). No more waiting on those Lambda testing framework's slow local testing or, worse, actually deploying to Lambda to get basic iterative feedback.
Any tests that require more that a few seconds tends to mean you get sucked into some distraction. When I'm coding I want to stay in the flow of it. Getting instant feedback from testing is awesome. Getting instant feedback from tests that are running exactly the same thing as production? That is just perfect. Unfortunately in this case, unlike my web services, it required faking something out (substituting Redis in for SQS) but I think it's low risk.
Even so, before final deployment I still choose to run the test suite against something with almost exact parity as production (basically only differing from production in stored database data). There could always be some difference. On teams I've been on, we've caught a few problems in those stages.
I also believe in the 'testing in production' ideas out there, to an extent. As long as we're not talking about only testing in production which usually makes no sense. There are still a number of problems you can catch ahead of time with a stage right before production that matches the infrastructure. In my case it's going to add around 10 minutes per actual deployment and I'm just fine with that given that it's automated and the potential value from avoiding an outage. But everyone has their own trade-offs to think about (context matters).
Meanwhile both my local development flow and the longer full integration test suite were both sped up massively.
Update: wrote a separate post going into more detail about process group launches and runit here.