
Single-query challenges in DynamoDB
You can end up doing a lot of legwork ensuring DynamoDB (DDB) queries will work for a use case. But it can give you huge advantages.
I'm going to use an example from Yupdates. One of the design tenets is to be fast for all feeds at all timestamps. It needs to feel instant no matter what feed you're looking through and no matter how many items in the history you want to explore.
DDB is the backbone for this. There are many factors and constraints that go into our database choices, and I can't cover the entire decision here. In this case, there are many reasons why caching isn't the answer (unless it is permanent and total, which would be unreasonably expensive). Delivering on the design tenet needed to start at the database itself.
I've run services that use DDB and saw the way many AWS services use it behind the scenes — all very confidence inducing. In the next year, Yupdates could easily be into the terabytes (still on the small side for DDB) and get single-digit millisecond read performance on the entire data set with low operational overhead.
The most recommended approach to designing a DDB table is to map out your access patterns ahead of time and then store the data in a way that matches what those queries need. You will end up with fast queries for everything you planned for, but you won't have the greatest ad-hoc query story. This is a database geared heavily towards OLTP, not OLAP.
Yupdates feeds may be configured with multiple inputs, each being an independent data source. Customers can add up to 50 inputs to each feed, and the items from all of them will appear combined, interleaved by timestamp. These configurations can be changed at any time.
We want a single query per customer page view to maximize performance. We don't want to filter the results from the database, either. We want the data to be laid out exactly — and ahead of time — for the query to be able to access the next N items to be shown in a page of N results.
It sounds like it might be simple, but the first issue is that we are not working with a stable feed. An input can be added or removed at any time. And when that happens, we need to add or remove the items that input is contributing.
Say the items were stored in the database like this:
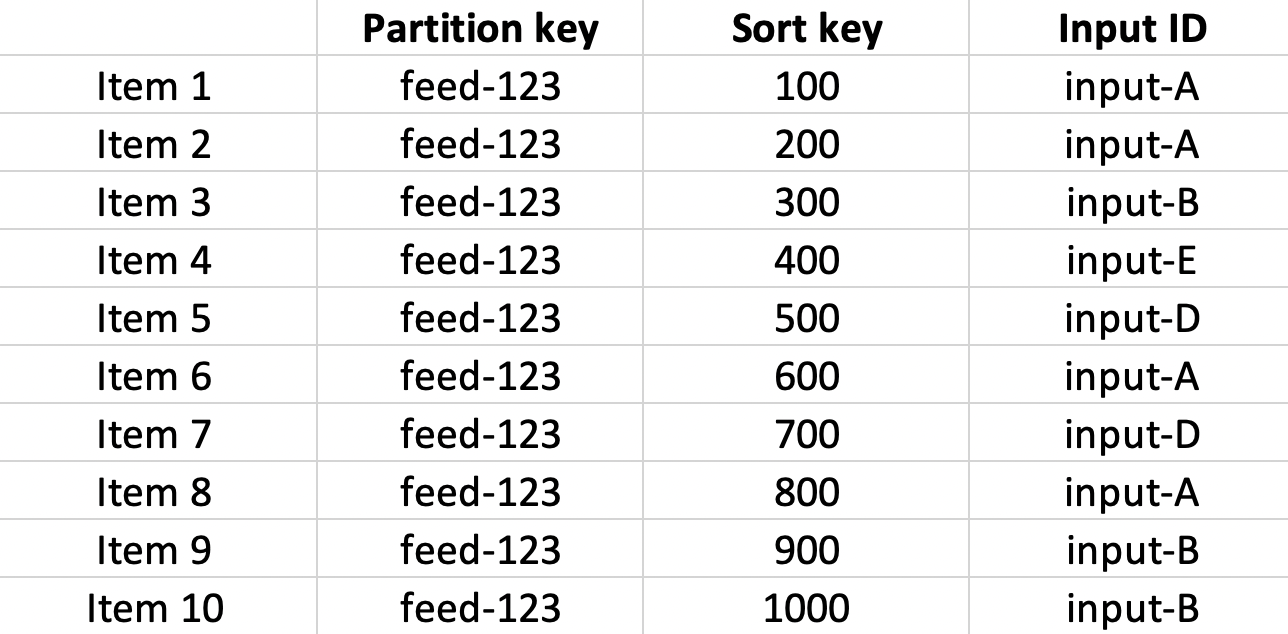
What DDB calls the "partition key" is the unique feed ID, and the "sort key" is the item timestamp. Together they make a composite primary key. You can query for all items with a particular partition key coupled with a range from the sort key.
In our example, querying for partition-key == feed-123 and 5 items, sort-key < 800 will get you items #3 through #7.
That's not the real syntax, but it's not important to the discussion to learn it right now.
Say the customer removes input A. So we delete any items from input-A, and the data now looks like this:
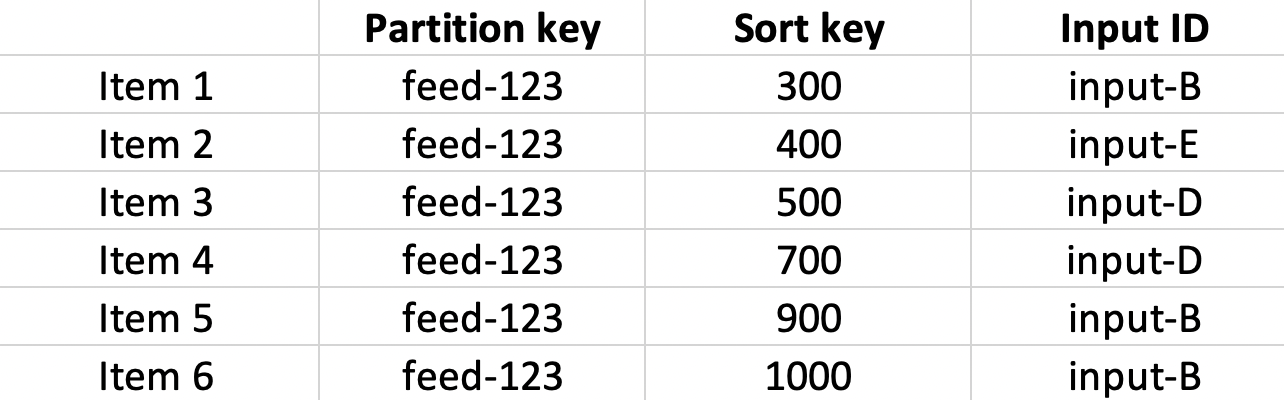
Repeating the query returns items #1 through #4 in this table.
But, oops, did we just delete the items we collected from an external source? Was that the only record of it?
No - that hard-earned data should be used and shared across many feeds. It happens even within the same feed if you have the same source set up multiple times with different settings.
So, these are not the items at all; these are more like pointers. And more than mere pointers, they need to carry all the data necessary to display the items (otherwise, we'd need more queries to get details about each item). This comes up a lot in these types of databases; this is denormalization. That data is all copied from the underlying input records.
You end up becoming a manual JOIN manager.
On top of that typical NoSQL problem, feed results need to be shown in a consistent order.
Each time a new input is added, the new items might contain timestamps already present in the existing feed items. If you have items with duplicate timestamps, they may come back in any order from the database. Refreshing a feed and seeing items switch around is not OK. An item could even disappear if it were at the edge of the page of results. You could get even wilder results from a feed of 500 items that share the same timestamp (it happens).
I'll omit the complicated solution to fixing that, and DDB doesn't allow duplicate sort keys to begin with, but the point is that many of the current items need to be analyzed when bulk-adding new ones.
All this work, and meanwhile, the feed should be able to be queried (uh oh). We want an atomic change so that the results aren't out of whack during this long recomputation window. Having random sets of items appear or disappear depending on when it's queried is a bad customer experience. The results should either be the pre or post configuration-change states, not an incorrect in-between state. Most importantly, we want to be able to back things out easily if there are unrecoverable errors.
DDB transactions won't work, mainly because there is a limit on how many writes/deletes you can do at once (100). A complicated series of transactions might be "good enough," roughly like a Saga pattern. Or you could lock the entire feed for a while, giving exclusive access to one process. Getting that right is notoriously hard, especially accounting for a process being able to die at any time, variable durations of work, etc.
The solution I arrived at, much to my initial horror, is to create a unique feed version for every new permutation of settings which changes as inputs are added and removed from a feed. The more permanent concept of "feed" becomes an indirection record to the "current" feed version.
All the analysis and preparation work can happen out of band, and the feed can be flipped over when it looks good. The switch can happen under a transaction on the off-chance there was a concurrent reconfiguration.
The main drawback is that it can involve a lot of copies. As these are "pointers," the size is not a problem. The main issue with copies is needing to pay for so many write operations.
With feeds capping out at 500 items, this is OK. When running the math in this particular system, there's a range where this is a viable option, and this is well below the cutoff. It all depends on how often you would need to do something like this, your cost model, the end benefits it unlocks, and the need for accuracy vs. eventual consistency. You'd need to do your own math, of course.
Another consequence is needing to garbage collect old feed versions. There was already a GC system in Yupdates, so that was not a barrier.
More extra work: caching which feed version is current. This is a tiny record, so it is very cheap, scales nicely, and the cache duration can be extra long. A lookup is sub-millisecond, and if the cache is empty or down, the DDB GET for the record is 1-2 ms.
Finally, reconfigurations needed to be rate-limited to prevent automated abuse from causing an unreasonable cost spike. No problem, everything is already rate-limited; this is a math and tuning issue.
There are other approaches. You could use filters, removing deleted items from query results. Even if you had DDB do this for you before returning results, it would add time and cost (you can end up querying 100s of items to find 20, and you still need to pay for that in their pricing system). Using a sparse global secondary index is another approach, and Yupdates uses them in many places; however, the extra cost and eventual consistency was unattractive in this case.
The 100-item transaction limit is still a problem in all the options I considered.
This was a lot of work, but it's for a good cause. These queries now take around 5 ms in practice.
The reconfiguration and query system is well tested and built on this database I'm highly confident about. Peace of mind is an important part of your design choices, too. These fast queries are not only one of the biggest selling points of the product (IMO); maintaining this part of the performance story is one of the things I'm least worried about.